Data Movement¶
Most processors and accelerators achieve optimal performance by keeping the kernel input data in “close” local memories on those processors (for example, CCMs). Meanwhile, the total amount of data that needs to be operated on is usually bigger than the sizes of those CCMs, so you must copy data into CCMs for processing.
The functions in the Data Movement Group assist with this moving (copying) of data. For further efficiency, the APIs allow data to be manipulated in several ways, thus allowing copy and manipulation to happen at the same time, rather than in two separate steps.
The supported transformations are described here and shown pictorially in Figure Data Movement Group Transformations
Copy - a simple copy operation only
Slicing - select a subset of a larger tensor and copy it to the destination tensor
Concatenation - copy the content of a smaller tensor into a larger one
Subsample - Reduce the size of the output by taking only every nth element from the source
Permute - Reorder dimensions of a tensor
Padding - Add zeros around the specified dimensions
More than one transform can be combined into a single operation.

Data Movement Group Transformations¶
The data movement APIs support both synchronous (blocking) and asynchronous (non-blocking) APIs. The caller can choose which is most suitable for their use-case. The functions are described in the following sections.
Synchronous Copy from Source Tensor to Destination Tensor¶
This function performs a blocking data copy from the source tensor to the destination tensor
according to the settings in the configuration structure, mli_mov_cfg. Any combination of the
previously-mentioned transformations can be specified. The destination tensor needs to contain a valid
pointer to a large enough buffer. The size of this buffer needs to be specified in the capacity
field of the destination tensor. The other fields of the destination tensor are filled by the
move function. The function returns after the complete data transfer completes.
For platforms with a DMA, the synchronous move function internally acquires one or more DMA
channels from a pool of resources. The application needs to use the function mli_mov_set_num_dma_ch
to assign a set of channels to MLI for its exclusive use. See section DMA Resource Management for a detailed
explanation.
mli_status mli_mov_tensor_sync (
mli_tensor *src,
mli_mov_cfg *cfg,
mli_tensor *dst);
where
mli_mov_cfgis defined as:
typedef struct {
uint32_t offset[MLI_MAX_RANK];
uint32_t size[MLI_MAX_RANK];
uint32_t sub_sample_step[MLI_MAX_RANK];
uint32_t dst_offset[MLI_MAX_RANK];
int32_t dst_mem_stride[MLI_MAX_RANK];
uint8_t perm_dim[MLI_MAX_RANK];
uint8_t padding_pre[MLI_MAX_RANK];
uint8_t padding_post[MLI_MAX_RANK];
} mli_mov_cfg_t;
The fields of this structure are described in Table mli_mov_cfg Structure Field Description. All the fields are arrays with
size MLI_MAX_RANK. Fields are stored in order starting from the one with the largest stride between the data
portions. For example, for a matrix A(rows, columns), shape[0] = rows, shape[1] = columns. The data move function
does not change the number of dimensions. The rank of the source tensor determines the amount of values that are
read from the array. The other values are “don’t care”.
The size of the array is defined by MLI_MAX_RANK.
Field Name |
Type |
Description |
|---|---|---|
|
|
Start coordinate in the source tensor. Values must be smaller than the shape of the source tensor. |
|
|
Size of the copy in elements per dimension. Restrictions: \(Size[d] + offset[d] <= src->shape[d]\) If \(size=0\) is provided, the size is computed from the input size and the cfg parameters. |
|
|
Subsample factor for each dimension. Default value is 1, which means no subsampling. For example, a subsample step of 3 means that every third sample is copied to the output. |
|
|
Start coordinate in the destination tensor. Values must be smaller than the memstride of the destination tensor. |
|
|
Distance in elements to the next dimension in the destination tensor. If zero, it is computed from input tensor and cfg parameters. |
|
|
Array to specify reordering of dimensions. For example, to convert from CHW layout to HWC layout this array would be {1, 2, 0}. |
|
|
Number of padded samples before the input data for each dimension. Padding is a virtual extension of the input tensor. Padded samples are set to zero. |
|
|
Number of padded samples after the data for each dimension. Padding is a virtual extension of the input tensor. Padded samples are set to zero. |
It is possible to combine multiple ‘operations’ in one move. In that the internal order of how the parameters are applied is relevant:
padding_pre/padding_post (using cfg->padding_pre and cfg->padding_post as described in figure mli_mov_cfg Structure Parameters for padding)
crop (using cfg->offset and cfg->size as described in figure mli_mov_cfg Structure Parameters for cropping)
subsampling (using cfg->sub_sample_step as described in figure mli_mov_cfg Structure Parameters for subsampling)
permute (using cfg->perm_dim)
write at offset (using cfg->dst_offset and cfg->dst_mem_stride)
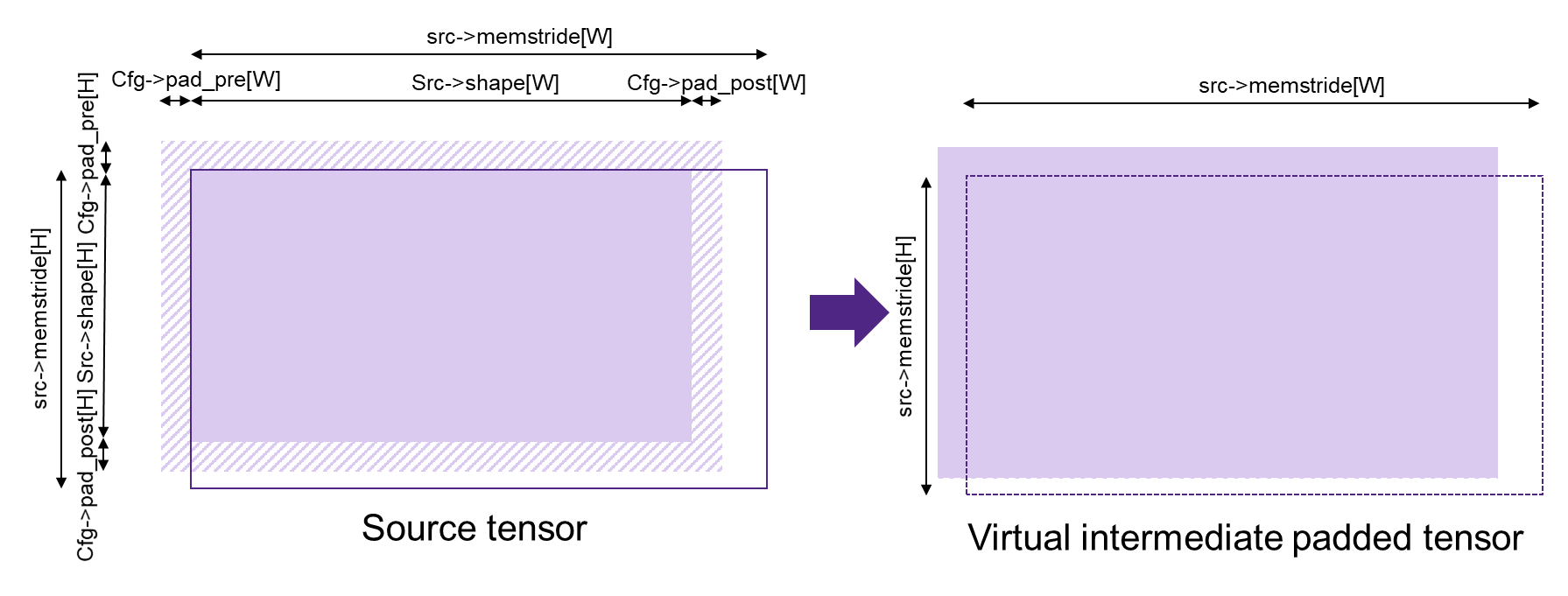
mli_mov_cfg Structure Parameters for padding¶
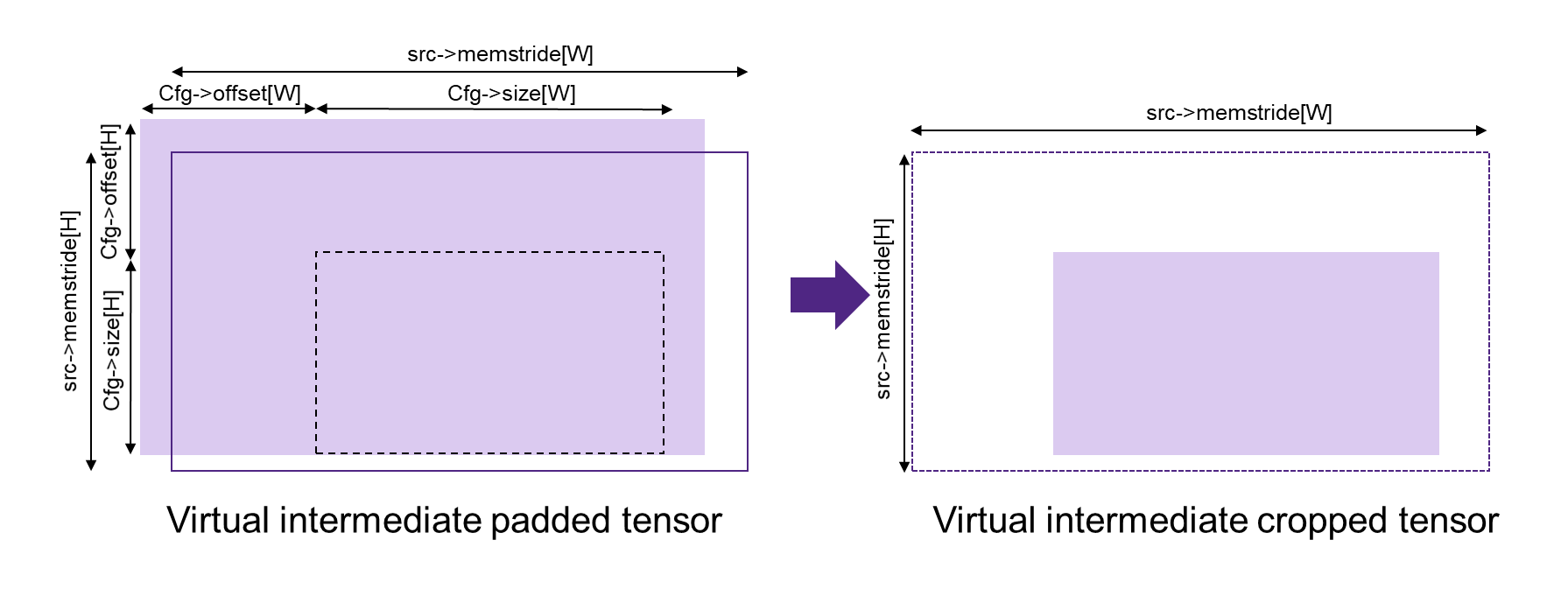
mli_mov_cfg Structure Parameters for cropping¶
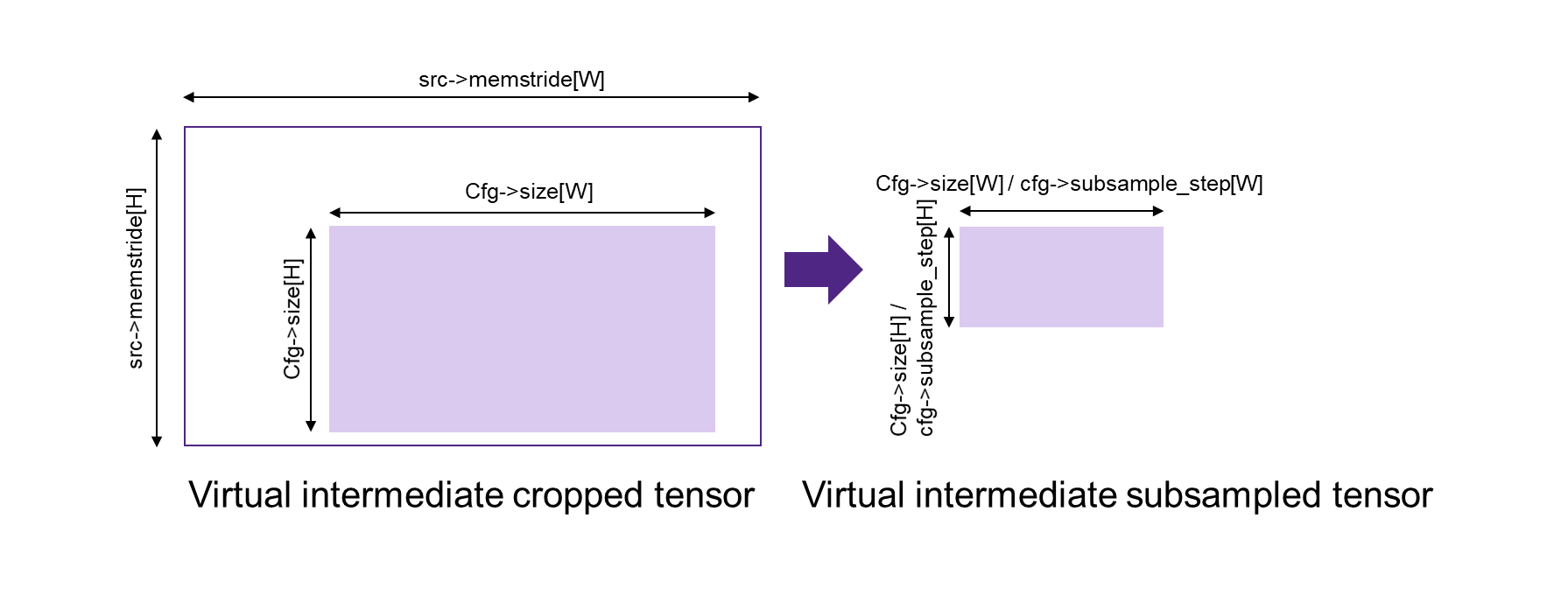
mli_mov_cfg Structure Parameters for subsampling¶
Ensure that you satisfy the following conditions before calling the function:
srctensor must be valid.
dsttensor must contain a valid pointer to a buffer with sufficient capacity (that is, the total amount of elements in input tensor). Other fields are filled by the kernel (shape, rank and element-specific parameters).Buffers of
srcanddsttensors must point to different, non-overlapped memory regions.
For src tensor of sa8 or sa32 types, and in case of per-axis quantization, the el_params
field of dst tensor is filled by the function using src quantization parameters.
The following fields are affected:
dst.el_params.sa.zero_point.mem.pi16and related capacity field
dst.el_params.sa.scale.mem.pi16and related capacity field
dst.el_params.sa.scale_frac_bits.mem.pi8and related capacity field
Depending on the state of the preceding pointer fields, ensure that you choose only one of the following options to initialize all the fields in a consistent way:
If you initialize the pointers with
nullptr, then corresponding fields from theintensor are copied todsttensor. No copy of quantization parameters itself is performed.If you initialize the pointers and capacity fields with the corresponding fields from the
intensor, then no action is applied.If you initialize the pointers and capacity fields with pre-allocated memory and its capacity, then a copy of quantization parameters itself is performed. Capacity of allocated memory must be big enough to keep related data from input tensor.
Some operations (like padding, concat, slice, subsample) when applied on the quantization axis will affect the
quantization parameters (e.g. If subsampling on the quantization axis is applied, also the quantization parameters
will be subsampled). For these cases the output tensor should contain valid pre-allocated memory buffers to get
correct quantization parameters. If this is not done, and the pointers are initialized with nullptr or with the
same pointers as the src tensor, the result is undefined.
In case of per-axis quantization of the src tensor, the axis needs to match the (permuted) quantization axis in the dst tensor.
A combination of per-axis and per-tensor quantization is not allowed.
In case of padding on the quantization axis, the quantization parameters for the padded area will be set to scale=1, scale_frac_bits=0, zero_point=0
Depending on the debug level (see section Error Codes) this function performs a parameter
check and returns the result as an mli_status code as described in section Kernel Specific Configuration Structures.
Helper Functions for Data Move Config Struct¶
When only one of the transformations is needed during the copy, several helper functions can be used to fill the config struct. These are described in Description of Helper Functions for Data Move Config Struct. The arguments to the function are copied into the cfg struct while the remaining parameters are set to their default values. In the case of multiple transformations, there is a generic helper function available or the user can manually fill the cfg struct parameters. Note that the mli_mov_cfg structure is described in detail in mli_mov_cfg Structure Field Description.
Function Name |
Description |
|---|---|
mli_mov_cfg_for_copy(
mli_mov_cfg_t *cfg)
|
Fills the cfg struct with the values needed for a full tensor copy and sets all the other fields to a neutral value.
|
mli_mov_cfg_for_slice (
mli_mov_cfg_t *cfg,
int* offsets
int* sizes,
int* dst_mem_stride);
|
Fill the cfg struct with the values needed for copying a slice from the source to the destination tensor.
|
mli_mov_cfg_for_concat(
mli_mov_cfg_t *cfg,
int* dst_offsets,
int* dst_mem_stride);
|
Fill the cfg struct with the values needed for copying a complete tensor into a larger tensor at a specified position.
|
mli_mov_cfg_for_subsample(
mli_mov_cfg_t *cfg,
int* sub_sample_step,
int* dst_mem_stride);
|
Fill the cfg struct with the values needed for subsampling a tensor.
|
mli_mov_cfg_for_permute(
mli_mov_cfg_t *cfg,
uint8_t* perm_dim);
|
Fill the cfg struct with the values needed for reordering the order of the dimensions in a tensor.
|
mli_mov_cfg_for_padding2d_chw(
mli_mov_cfg_t *cfg,
uint8_t padleft,
uint8_t padright,
uint8_t padtop,
uint8_t padbot,
int* dst_mem_stride);
|
Fill the cfg struct with the values needed to add zero padding to a tensor in CHW layout.
|
mli_mov_cfg_for_padding2d_hwc(
mli_mov_cfg_t *cfg,
uint8_t padleft,
uint8_t padright,
uint8_t padtop,
uint8_t padbot,
int* dst_mem_stride);
|
Fill the cfg struct with the values needed to add zero padding to a tensor in HWC layout.
|
mli_mov_cfg_all(
mli_mov_cfg_t *cfg,
int* offsets,
int* sizes,
int* subsample_step,
int* dst_offsets,
int* dst_mem_strides,
uint8_t* perm_dim,
uint8_t* pad_pre,
uint8_t* pad_post);
|
This function fills the cfg struct with the values provided as function arguments. It is recommended that applications use this function instead of direct structure access, so that application code does not have to change if the structure format ever changes.
|
Asynchronous Data Move Functions¶
Certain implementations might choose to perform other processing while the move operations are in progress. This is especially helpful for systems that use a DMA to move the data. The asynchronous API can be used in that case.
The operation is divided into three separate steps, each with corresponding APIs:
Preparation (DMA programming)
Start processing (trigger DMA)
Done notification (DMA finished, data is ready) – via either callback or polling
Between steps 2 & 3, the application can do other processing.
These APIs use the mli_mov_handle_t type. The definition of this type is private to
the implementation, but to avoid dynamic memory allocation the definition is put in
the public header file. This way the caller can allocate it on the stack.
Preparation¶
The mli_mov_prepare function is called first to set up the transfer. The functionality
of this function varies depending on the implementation, but it often performs DMA
initialization. Table mli_mov_prepare Parameters describes the parameters of this function.
mli_status
mli_mov_prepare(mli_mov_handle_t* h, const mli_tensor* src, const mli_mov_cfg_t* cfg, mli_tensor* dst);
Parameter Name |
Description |
|---|---|
|
Pointer to a handle obtained by |
|
Pointer to Source tensor |
|
Pointer to a cfg structure (see mli_mov_cfg Structure Field Description for details) |
|
Pointer to Destination tensor |
Depending on the debug level (see section Error Codes), this function performs a parameter
check and returns the result as an mli_status code as described in section Kernel Specific Configuration Structures.
Start Processing¶
The mli_mov_start function is called to begin the previously-setup transfer. Table
mli_mov_start Parameters describes the parameters of this function. If this function
is called without first calling mli_mov_prepare for a given handle, the DMA might
be triggered with an old configuration leading to undefined behavior. In a debug build,
an assert is triggered.
mli_status
mli_mov_start(mli_mov_handle_t* h, const mli_tensor* src, const mli_mov_cfg_t* cfg, mli_tensor* dst);
Parameter Name |
Description |
|---|---|
|
Pointer to handle used when calling
associated |
|
Pointer to Source tensor |
|
Pointer to a cfg structure (see mli_mov_cfg Structure Field Description for description) |
|
Pointer to Destination tensor |
Depending on the debug level (see section Error Codes), this function performs a parameter
check and returns the result as an mli_status code as described in section Kernel Specific Configuration Structures.
Done Notification - Callback¶
You can register a callback function which is called after the data move is finished. A callback is registered with the following function. The parameters are described in Table mli_mov_registercallback Parameters.
mli_status
mli_mov_registercallback(mli_mov_handle_t* h, void (*cb)(int32_t), int32_t cookie);
Parameter Name |
Description |
|---|---|
|
Pointer to handle used when calling associated
|
|
Pointer to user-supplied callback function |
|
Parameter passed to callback function |
Note
If a callback is used, mli_mov_registercallback must be called before mli_mov_start
to avoid race conditions. A race condition would arise if the DMA transaction is faster
than the registration of the callback and would cause the callback to not be called.
If a callback function has been registered, this callback is called after the DMA transaction completes, and the value of cookie is passed in as an argument.
Done Notification - Polling¶
You can also simply poll for the completion of the DMA transaction using this function:
bool
mli_mov_isdone(mli_mov_handle_t* h);
This function takes a pointer to the handle used for mli_mov_prepare and returns:
True - if the transaction is complete
False - if the transaction is still in progress
You can also wait for the DMA to compete using the following function:
mli_status
mli_mov_wait(mli_mov_handle_t* h);
This function takes a pointer to the handle used for mli_mov_prepare and returns
after the transaction completes or in case of an error.
Restrictions for Source and Destination Tensors¶
src and dst tensors for all functions of asynchronous data move set must comply to the following conditions:
srctensor must be valid.
dsttensor must contain a valid pointer to a buffer with sufficient capacity. (that is, the total amount of elements in input tensor). Other fields are filled by the kernel (shape, rank and element-specific parameters).Buffers of
srcanddsttensors must point to different, non-overlapped memory regions.
For src tensor of sa8 or sa32 types, and in case of per-axis quantization, the el_params
field of dst tensor is filled by the function using src quantization parameters.
The following fields are affected:
dst.el_params.sa.zero_point.mem.pi16and related capacity field
dst.el_params.sa.scale.mem.pi16and related capacity field
dst.el_params.sa.scale_frac_bits.mem.pi8and related capacity field
Depending on the state of the preceding pointer fields, ensure that you choose only one of the following options to initialize all the fields in a consistent way:
If you initialize the pointers with
nullptr, then corresponding fields from theintensor are copied todsttensor. No copy of quantization parameters itself is performed.If you initialize the pointers and capacity fields with the corresponding fields from the
intensor, then no action is applied.If you initialize the pointers and capacity fields with pre-allocated memory and its capacity, then a copy of quantization parameters itself is performed. Capacity of allocated memory must be big enough to keep related data from input tensor.
DMA Resource Management¶
The MLI API permits multiple mov transactions occurring in parallel, if the particular target hardware has a DMA engine which supports multiple channels. MLI also assumes that other parts of the system might want to access the DMA Engine at the same time and relies on the application/caller to provide it with a pool of available DMA channels that can be used exclusively by MLI. The following functions are used for this purpose:
The mli_mov_set_num_dma_ch is called once at initialization time to assign a set of
channels to MLI for its exclusive use.
mli_status
mli_mov_set_num_dma_ch(int ch_offset, int num_ch);
ch_offset- first channel number that MLI should use
num_ch- max number of channels that MLI can use
The asynchronous move functions require a handle to a DMA resource. This handle can be
obtained from the pool using mli_mov_acquire_handle:
mli_status
mli_mov_acquire_handle(int num_ch, mli_mov_handle_t* h);
num_ch- Number of DMA channels required for this move. Certain complex transactions might be more efficient when multiple channels can be used. By default, a value of 1 should be used.
mli_mov_handle_t* h- Pointer to a handle type which is initialized by this function
After the move has completed, the resources must be released back to the pool to avoid exhaustion:
mli_status
mli_mov_release_handle(mli_mov_handle_t* h);
mli_mov_handle_t* h- Pointer to a handle type which is used by the now-completed transaction
Depending on the debug level (see section Error Codes) this function performs a parameter
check and returns the result as an mli_status code as described in section Kernel Specific Configuration Structures.
Note
The synchronous move function mli_mov_tensor_sync manages these DMA operations internally.